

从未知到MAX:一家芯片设计企业的算力优化之路
摘 要
近一年来,在高性能计算元件供给困难的背景下,芯片设计企业开始探索多种途径解决算力困难问题,抓住芯片行业历史性机遇期。
某系统级芯片设计企业A借助网宿MSP高性能计算(HPC)行业解决方案,一站式解决粗放式算力运营模式下的算力扩容、算力管理、成本优化等问题,实现了统一管理效率提升50%,生产效率提升30%,并节省调度管理费用上百万。
近年来全球芯片持续缺货,而中国芯片产业在政策支持下,保持高速成长。
身处其中的某知名系统级芯片设计企业A是又喜又忧:喜的是手里的订单量翻番;忧的是,芯片仿真模拟对算力的需求呈指数级增长,但当前高性能计算元器件价格上涨甚至断货,严重推高了芯片企业采购算力的成本和难度,使得企业A的算力资源眼看就无力承接新增订单了。
于是,企业A决心进行系统性的算力优化,加快改变粗放的算力运营模式,摆脱算力紧张对业务扩张的掣肘,实现降本增效。
算力优化环环相扣,企业A发现,这些瓶颈需要突破:
No.1 买断式算力采购难救急
这张来自EDA软件厂商Cadence的图,概括了芯片设计企业在算力扩容上的节奏。
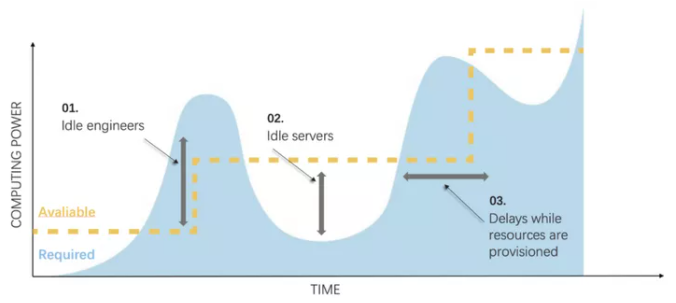
图中黄色虚线表示现有算力资源规模,蓝色区域表示资源需求量。当订单突增,计算资源需求暴涨时,企业追加购入资源;需求回落时,则出现资源闲置。买断式算力资源采购滞后、灵活性差的问题凸显。
企业A过往也是如此,当突发订单到来时只能临时加购服务器,扩充至本地计算集群中。然而,一方面,现今芯片的迭代速度越来越快,一个设计项目的周期往往只有几个月,再遇上芯片缺货导致的采购难,等机器到位,离deadline没几天了。
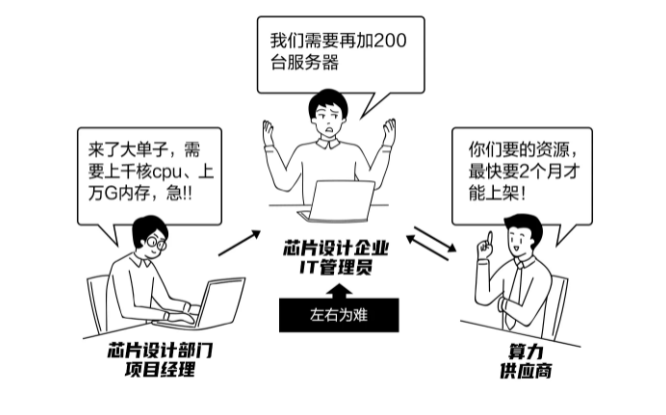
另一方面,加购的资源如果没有后续订单稳定“光顾”,就要闲置浪费,白白折旧。因此,一次加购多少机器合适,总要让采购部门十分纠结。
近年来,Cloud HPC(云端高性能计算)的出现,打破了买断式算力采购模式的局限,算力的扩缩变成分分钟的事情。而且,云服务器的迭代更新速度远高于买断模式的三年一换,最新硬件上架周期甚至能缩短到以小时计。
因此,企业A萌生了引入混合算力的想法:在本地资源的承载核心计算任务的基础上,结合云端算力处理突发的计算需求溢出,岂不两全其美。
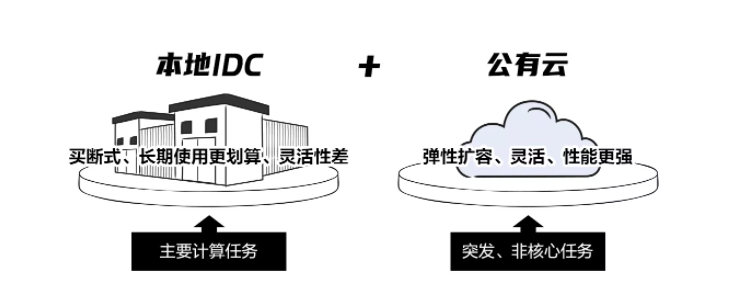
但要想真正用好本地+公有云的混合架构,做到降本增效,还有更多问题需要解决。
No.2 粗放式算力管理 浪费严重
云端算力虽然灵活,却有一个扎心的问题——贵。主流公有云平台HPC实例的计费模式甚至已经细化到了按秒计费。在不改变大手大脚的算力使用习惯时就上云,增开实例很容易,起飞的账单可就不美丽了。
因此企业A认为在上云之前,应当先将本地算力资源的利用率提高到100%。而以下两个环节都是浪费资源的大漏勺:
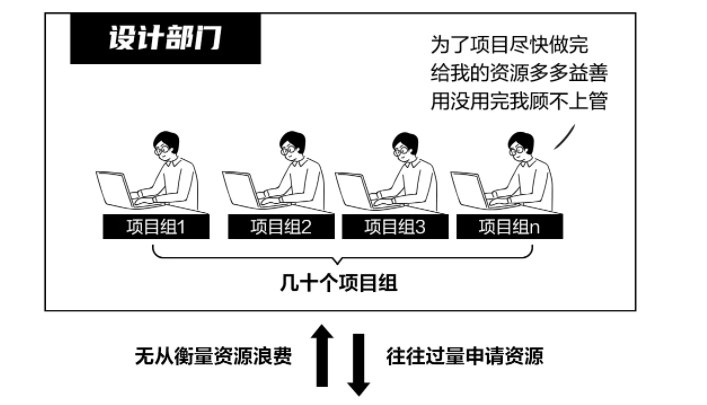
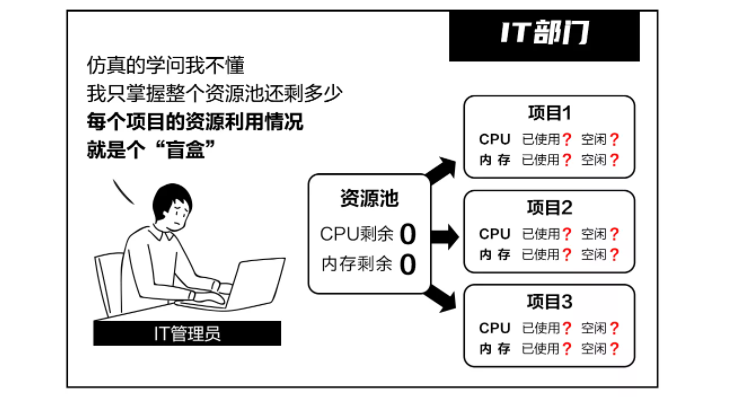
a.资源分配
业务部门追求项目进度效率,常常过高估计所需资源。而IT部门却无从监测各个项目对资源的实际利用率。当资源池被分配完毕,后面的任务开始排队等待时,实际上还有大量闲置在项目上的资源没有被及时回收,造成浪费。
b.资源调度
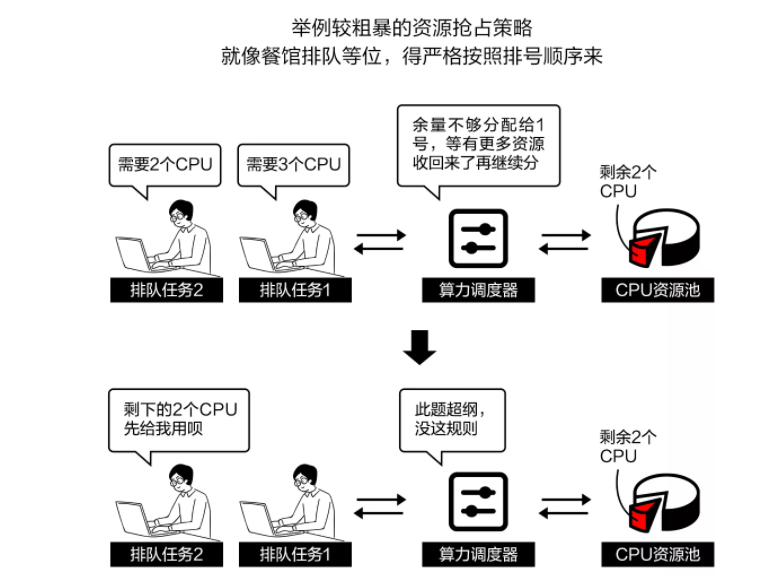
企业A的本地算力集群现有近一千个节点,项目多时,运行五、六千个任务是常事,需要依赖调度器尽可能利用紧张的算力资源,跑更多任务。
出于成本考虑,企业A使用的调度器是开源的OpenLava。而OpenLava调度策略恰恰相对简单粗暴,对资源的利用率不够高。每个节点都有一点资源没被用上,积少成多,也是一笔不小的浪费。
并且,除了资源利用率不高之外,OpenLava还有以下局限性:
由于版权问题已被禁用
不支持溢出上云
不具备项目视角的资源监控
这些缺陷让IT部门不得不考虑更换调度器,但若改用商业版的Spectrum LSF调度器,需要增加上百万的License购买成本。
唯一还在维护的纯开源调度器Slurm,拥有容错率高、支持异构资源、高度可扩展、适用性强等优势,60%的全球Top 500的超算中心都在使用。但改用Slurm还面临着学习成本高、开发需求多等问题,是否下决心切换至Slurm,又让IT部门陷入了纠结。
No.3 混合编排学习成本和试错风险高
除了算力管理水平问题,CloudHPC本身的使用门槛也不低。企业A此前从未接触过公有云,IT部门对上云的一系列实操问题,也毫无处理经验。
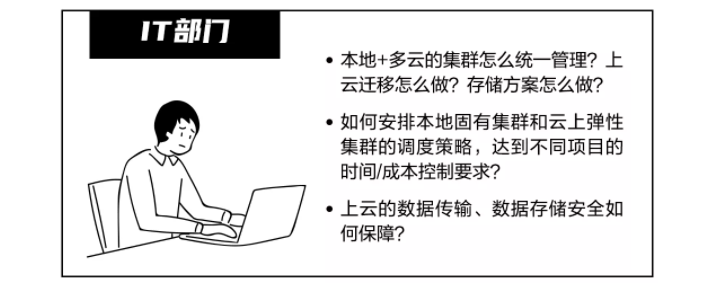
每家公有云产品和服务种类繁多,使用方式也不一样,如果自己摸索,势必要面临不小的学习成本和试错风险的压力。
No.4 混合算力 成本难核算
增加算力本质是为了缩短计算时间,更快地完成项目,接更多订单。但算力成本若超过订单的收入,就不划算了,因此需要衡量投入产出比,做资源采购预算的规划。特别是上云后计算资源可以近乎无限扩容,对资源成本的管控提出了更高的要求。
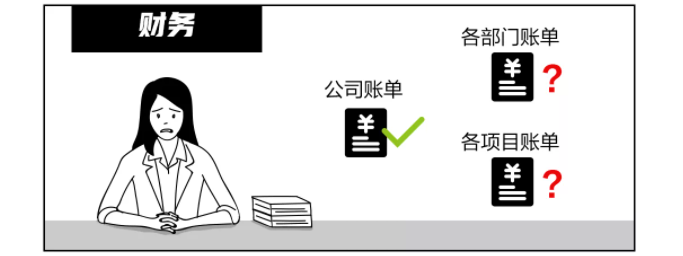
精细化的成本管理需要对每个项目的成本投入进行核算,但企业A 的账单系统不支持以项目粒度分摊成本费用。尤其是上云后,云账单名目更加复杂,本地+云上资源混合,又如何将费用分摊到各个项目,核算投入产出比呢?
面对以上症结,企业A开始寻求算力优化解决方案。但市面上的芯片行业方案,无论是做云上EDA环境构建的,还是做多云统一纳管,都不够贴合他们的实际业务情况,不能真正解决系统性的算力资源优化,降本增效的问题。直到他们在AWS的推荐下,找到了网宿。

针对高性能计算行业面临的算力扩容、算力管理、成本优化等问题,网宿MSP推出高性能计算(HPC)行业解决方案,深入业务视角,以产品+服务的闭环,助力企业实现一站式、精细化的本地+云的算力资源全生命周期管控。
No.1 算力管理:不浪费一个CPU
网宿云管平台HandyOps基于Slurm调度器开发了完整的本地+云算力管理能力,在承袭了Slurm容错率高、支持异构资源、高度可扩展、适用性强等优点的基础上,聚合了全局数据监控、管理报表、项目/租户/作业/策略管理等功能模块,即开即用,无需开发。
通过HandyOps的控制台提交各种计算任务后,系统会根据任务优先级,配置不同的调度策略(如成本优先策略或时间优先策略),灵活调度算力。
网宿的可视化全局数据监控,为企业A解决了资源监控缺少业务视角的瓶颈,支持从项目、任务、队列和用户等维度进行资源状况监控、输出报表,并支持对不同层级设置不同的查看权限,每个项目、每个设计师实际用量一目了然。当项目中出现闲置资源时,IT管理员能够及时回收,重新分配。

在网宿的集成调度系统下,企业A完成了向算力精细化管理的转变,实现了现有资源达到100%充分利用后才会出现任务排队的目标。
No.2 算力扩容:一键上云救急 高效混合编排
当突发订单到来,本地算力集群无法及时完成计算任务时,通过网宿HandyOps平台,可以快速向公有云平台扩容,一键完成云上算力集群创建,本地+云上资源统一纳管,既消除了本地算力资源难以弹性伸缩的局限,也避免了纯租用云资源的模式成本过高的问题。
在上云的数据安全保障上,网宿SD-WAN提供到公有云的高速直连加密链路,结合云端数据加密存储、安全审计技术,从传输到存储全链路封堵数据外泄。
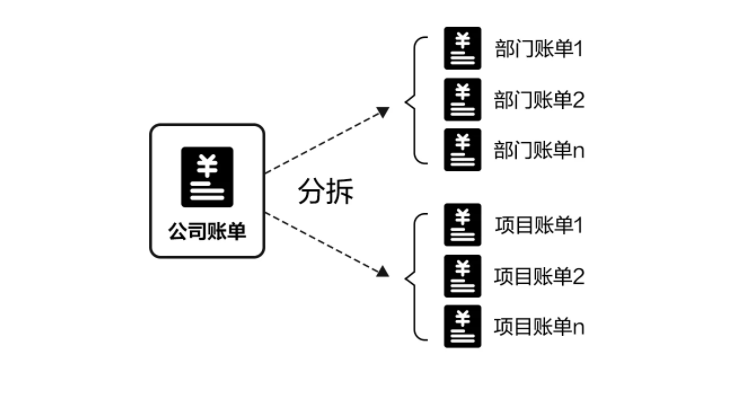
No.3 成本优化:业务视角账单核算
网宿提供本地+云上统一账单管理,支持部门粒度与项目粒度账单分摊,预测账单趋势,为财务部门核算投入产出比、制定采购预算提供有效的决策依据。同时,网宿MSP团队还基于平台优化报告,提供成本优化建议,进一步协助企业A降本增效。
在网宿MSP高性能计算行业解决方案的帮助下,企业A既免去了改用商业版调度器要花费的上百万license费用,又实现了统一管理效率提升50%,生产效率提升30%,成功降本增效。
.jpg "DDoS防护10G免费试用")