

爬虫“助攻”网站内容抄袭 平台知识产权谁来保护?
4月26日,我们迎来了第19个“世界知识产权日”,在知识产权越来越受到重视的今天,我们来谈谈爬虫与知识产权保护之间不得不说的故事。
日前,上海市杨浦区人民法院开庭审理了一起利用“爬虫软件”未经授权抓取各网文版权方小说达数千部,供读者免费阅读并以广告形式非法赢利的案件,两名被告人当庭表示认罪、悔罪,并表示“倾家荡产”对版权方予以赔偿。
在“内容为王”的当下,内容数据价值日益凸显,爬虫技术引发的内容侵权案例越来越多。
数据统计显示,互联网上50%的流量是来自于爬虫的,而在某些特定行业中甚至有网站流量90%都是来自爬虫的极端案例。房产中介网站、电商平台、点评分享等网站都是爬虫特别喜欢光顾的目标,新闻媒体、自媒体等内容类平台更是重灾区。
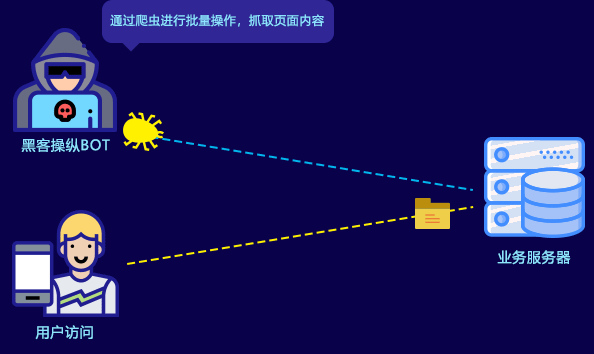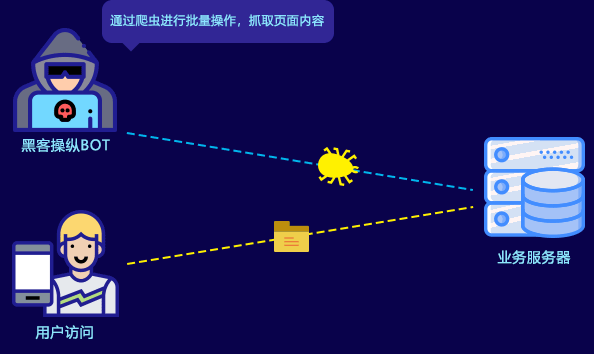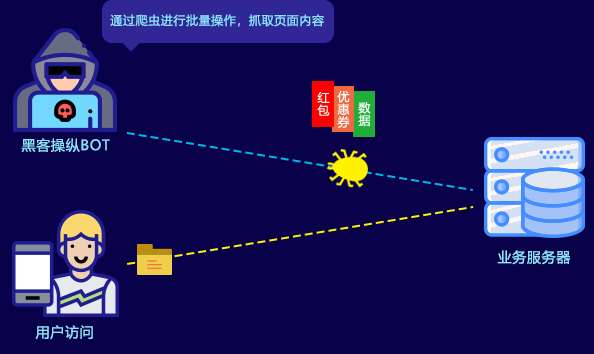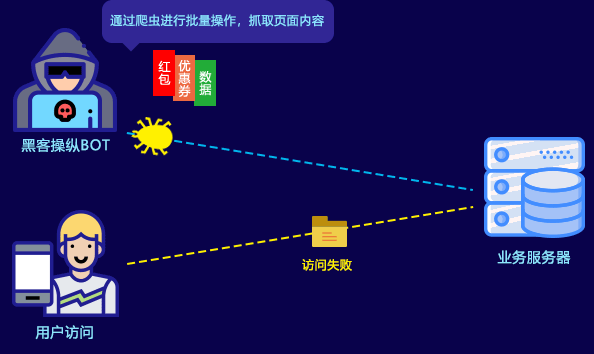
对于内容类平台来说,网站内容被爬虫抓取后二次传播,原创内容失去独家性,由此带来的是流量被分流和进一步的收入损失,以及更长远的品牌伤害。
此外,恶意爬虫的访问行为,也占用大量的带宽和服务器性能,影响正常用户访问,直接给被爬网站带来大量额外的成本支出。如何将恶意爬虫拒之门外,成为各类网站运营者面临的共同问题。
对抗有害爬虫,都有什么操作?
对抗恶意爬虫,常见的技术手段包括验证码、IP限速,User-Agent限制、Url访问限速等,但随着爬虫手段的越来越高明,上述方法的有效性也越来越低。
在尽力阻止爬虫入侵的同时,也有网站尝试提高爬虫爬取的门槛,比如用图片来渲染价格等关键信息,人眼可见,机器识别不出来;还有反爬团队,在内容里“投毒”,让爬虫抓取到不该抓取的内容,增加后期数据清洗的难度。
但以上种种手段,都无法完全杜绝爬虫。随着AI技术的发展,更是有一些公司打出“AI爬虫”的招牌,让爬虫的行为更接近真实用户。
在这种情况下,如何分辨正常用户和爬虫变得更加困难也更加重要,以其人之道还治其人之身,利用AI手段来反制爬虫,是当下反爬技术的新思路。
网宿AI爬虫防护服务
防护恶意爬虫攻击,关键在于精准识别真实用户流量和爬虫流量,并采取相应的管理措施。
网宿业务安全(Bot Guard)将数据分析与机器学习有效地结合起来应用于爬虫管理领域,基于网宿平台海量的用户和爬虫访问样本,结合机器学习算法,得到不断更新的识别模型,捕获异常访问。
为了绕过爬虫管理措施,攻击者不断调整爬取策略。因此,反爬技术也需要不断升级。网宿业务安全具有强大的智能纠错手段,结合IP信誉库,威胁情报库的过滤,动态调整防护策略,做到先于黑产一步,及时捕获攻击,生成最接近完美的防护策略。
基于对恶意爬虫行为的深度学习,网宿业务安全精准识别出正常用户与恶意爬虫之间的微小差异,同时利用恶意爬虫的一些特性来布设陷阱,诱导爬虫进入,达到主动防护目的,为企业网站营造健康的运营环境。
.jpg "DDoS防护10G免费试用")